
History, AI, and Non-Consumption: Part II, The Innovation Paradox
Exploring Innovation Lifecycles through the Lens of AI

In part I of this series, we delved into the history of AI, journeying through periods of both promise and stagnation known as "AI Winters." Today, we're zooming in on the “why” behind these winters, examining the concept of "nonconsumption" and how it relates to AI's adoption. By the end of this post, you'll understand the different types of innovations, what nonconsumption is, and how it has shaped AI's trajectory.
The Types of Innovations
Before delving into nonconsumption, it's important to get a hold on the fundamentals of innovation and its various forms. Innovation is not one-size-fits-all, different types of innovation trigger distinct responses in the market. This section will cover how these innovations influence both supply and demand, and how they shape market dynamics. Understanding this interplay matters to grasp how innovations, such as AI, can transform industries and create new opportunities.
Supply-Side Vs. Demand-Side
When we look at innovations, we have to consider two sides: supply and demand. Supply-side innovations act as a catalyst for enhanced production efficiency, potentially fattening profit margins. This is not merely about tweaking a few nuts and bolts, it involves engineering overhauls across various segments of the supply chain or the value stream. Those advancements can lead to increases in the quantity of supply available on the market and sometimes, even shifts in the supply curve. Picture a machine running smoother and faster, churning out higher-quality goods at a quicker rate.
Demand-side Innovations, on the other hand, look into their impact on consumer demand. They affect how consumers perceive and desire products. A great demand-side innovation would result in outward shifts in the demand curve (e.g., by creating new markets) or increases in the quantity demanded. An example would be introducing a revolutionary gadget that everyone didn't know they needed, but now can't imagine living without once they used it (sounds familiar?).

Disruptive Vs. Sustaining
Every now and then, we experience technological breakthroughs, while often exciting advancements, they don't always translate into market success or new products/services. They are fundamental discoveries or inventions that push the boundaries of what's possible. However, it's the disruptive innovations built upon these breakthroughs that truly reshape markets. Example of breakthroughs:
Quantum Computing: While still in its early stages, quantum computing represents a leap in processing power, promising to solve complex problems beyond the reach of classical computers. This breakthrough has the potential to disrupt industries like pharmaceuticals, materials science, and finance, but its full-fledged applications are still years away (for now).
Brain-Computer Interfaces (BCIs): BCIs, like Neuralink's projects, aim to connect the human brain directly to computers, potentially enabling new forms of communication and treatment for neurological disorders. While groundbreaking, widespread adoption and market disruption are still a long way off, though there are signs of it starting:
Genetic Engineering: CRISPR-Cas9 and other gene-editing tools offer immense possibilities for treating genetic diseases, modifying crops, and even creating designer babies. However, ethical concerns, regulatory hurdles, and technical challenges mean that the full disruptive potential of genetic engineering is yet to be realized.
Building upon breakthroughs, disruptive innovations introduce new products or services that significantly alter the market landscape. These innovations often create new market opportunities by offering cheaper, more convenient, or more accessible alternatives to existing products (we will discuss nonconsumption in the next section). Disruptive innovations can shift the demand curve to the right as they attract new customers who were previously underserved or not served at all by existing products.
It’s important to note that disruptive innovations are “disruptive” because of their impact on aggregate demand for an underserved need (either latent or blatant). Here are some examples of disruptive innovations and the breakthroughs they were built upon.
Smartphones (Disrupting Mobile Phones and PCs): Smartphones, like the iPhone, are built upon breakthroughs in touchscreen technology, mobile processors, and wireless communication. They disrupted the traditional mobile phone market and even impacted the personal computer industry by providing a more convenient and versatile alternative.
E-commerce (Disrupting Retail): Amazon and other e-commerce platforms leveraged breakthroughs in internet technology, logistics, and online payment systems. They disrupted brick-and-mortar retail by offering a wider selection, competitive prices, and the convenience of shopping from home.
Ride-sharing (Disrupting Taxis): Companies like Uber and Lyft utilized breakthroughs in GPS technology, mobile apps, and real-time data processing. They disrupted the taxi industry by offering on-demand rides, transparent pricing, and a more user-friendly experience.
Most technological breakthroughs undergo several epochs/phases before they are finally usable enough (commercially viable) to cause disruption in markets (impacting demand curves). Not all breakthroughs lead to commercially viable products or services that can disrupt markets.
Sustaining innovations, on the other hand, are incremental improvements that maintain and enhance the competitiveness of existing products or services within established markets. Unlike disruptive innovations that create new markets or alter existing ones (by shifting demand curves), sustaining innovations focus on enhancing the features, performance, or efficiency of current offerings. These innovations are important for businesses to keep pace with market demands and ensure customer satisfaction and continued market relevance.
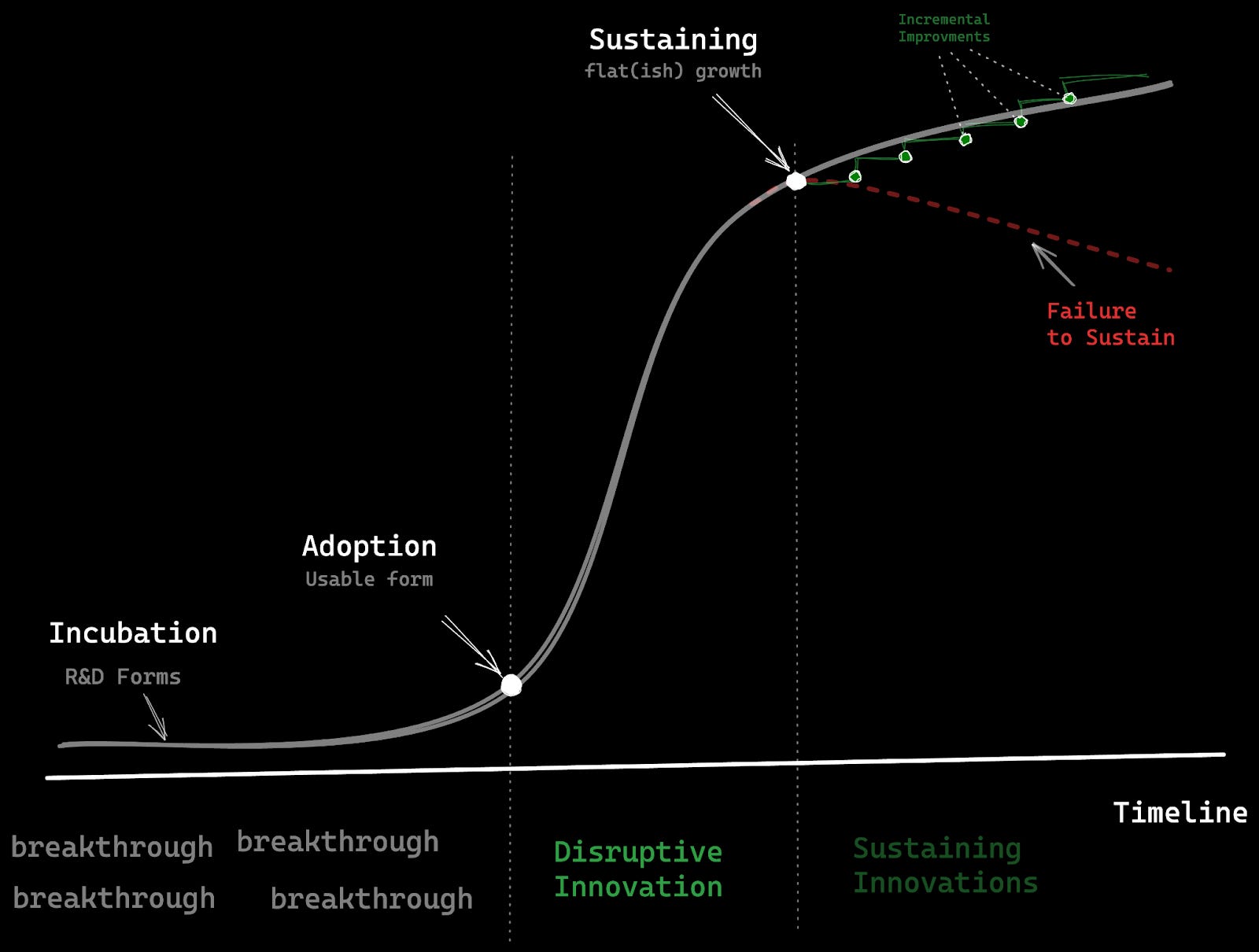
If we put it all in a chart, it would start with an incubation phase, where breakthroughs can emerge but remain “researchy”, lacking application and viability. As these breakthroughs evolve, a usable product could be developed, getting us to the Adoption phase. This stage typically shows rapid growth due to Disruptive Innovation, where the application of breakthrough technology reshapes markets and unlocks new possibilities by fulfilling previously unmet needs. With time, the innovation enters the Sustaining phase, where growth stabilizes and is driven by incremental enhancements to the existing product. However, failure to maintain or sustain can lead to a decline, underscoring the importance of incremental improvements to remain competitive (even starting a new “S-curve” with another disruptive application).
This “S-curve of Innovation” shows the evolution from breakthroughs to commercially viable products that can be disruptive but must be sustained.
To go a step further, here is a diagram that shows how innovations interact with supply and demand dynamics, leading to different types of market impacts.

Now that we understand the types of innovation, let’s explore in more detail the main drivers of disruptive innovations, especially nonconsumption.
Nonconsumption
It does not matter if there is a breakthrough if no one can make use of it. As described in the previous section, breakthroughs can only become disruptive if they can be consumed/used, which is not always the case. Welcome nonconsumption!
Nonconsumption typically describes a scenario where potential customers are underserved by the current market offerings. These customers either cannot afford the existing solutions, do not have access to them, or find that the solutions do not perfectly meet their needs. Nonconsumption can be an opportunity for businesses to innovate and create products or services that address these unmet latent AND blatant needs, thus turning nonconsumers into consumers. It is also a risk to established companies (aka incumbents) that are too focused on serving their existing customer base but forgo opportunities outside of their comforting bubble, leaving more breathing room for startups (the new entrants).

Nonconsumers usually fall into one of the two categories:
Underserved nonconsumers: those who do not have access to a product or service due to various barriers such as cost, lack of information, lack of infrastructure, etc. For example, due to a lack of infrastructure, people in rural areas without access to high-speed internet are nonconsumers of streaming services/social networks and broader knowledge in general.
Overserved nonconsumers: those who do not use a product or service because it exceeds their needs or is too complex. For example, someone who only needs a basic phone for calls and texts but is offered a high-end smartphone with features they won't use is an overserved customer:
Clayton Christensen introduced me to the concept through his book, “The Innovator’s Solution.” In it, he discusses how new-market disruptions can target non-consumption by creating products that enable a larger population of people, who previously lacked the money or skill, to begin using a product and doing the job for themselves. Also see Targeting nonconsumption: The most viable path to growth - Christensen Institute
Note: brand plays a role here as well. Sometimes, nonconsumption can be by design via positioning/targeting a specific slice of consumers. This usually happens via brand design, that said, even then companies with great brands are at risk of disruption. We probably will talk about this in more detail in upcoming posts.
AI Winter Nonconsumption
In part I, we journeyed through the peaks and valleys of AI history and covered AI winters. However, we stopped short of exploring the reasons behind them. Winter came, multiple times actually, but WHY? Let’s go behind that wall today!

Take a quick look at your AI scroll, and cast your mind back to the mid-80s, when AI had one of its highest peaks in history. Back then, expert systems were seeing some signs of commercial viability as companies such as IBM, FMC, Toyota, American Express, and others started to find use cases for it. This led to renewed excitement and hope up until 1987, when expert systems started to show limitations and struggled to handle novel information and situations that fell outside its pre-programmed knowledge base, i.e., expert systems underserved consumers, and the tech was way behind in serving the needs properly, as a result, was non-consumable.
ℹ️ The spike in the graph does not reflect the demand curve but rather content generated, which is a rather poor proxy to adoption, but it’s all that we have in that timeline beyond the narratives described in the previous post.
Parallel to expert systems, many theories were getting close to actionable forms, especially for neural networks with Hopfield nets, Boldtzman machines, perceptrons, and backprop networks, see A Very Short History of Artificial Neural Networks | by James V Stone for more details. So at this point, the mid 80s, most of AI theories were formulated. Since the 50s, there have been multiple knowledge breakthroughs, yet no disruption on the horizon (remmember disruption hinges of demand). One could say that expert systems ALMOST did it, but it was a short dream back then.

So really, why?
With the benefit of hindsight, the field of artificial intelligence stems from the research originally done on Hopfield nets, Boltzmann machines, the backprop algorithm, and reinforcement learning. However, the evolution of backprop networks into deep learning networks had to wait for three related developments: 1) much faster computers, 2) massively bigger training data sets, and, 3) incremental improvements in learning algorithms ~ from A Very Short History of Artificial Neural Networks | by James V Stone
One way I would sum it up is AI winters were a result of a negative consumption gap where expectations of what’s possible from AI exceeded what was being delivered, due to many factors such as much faster computers, massively bigger training data sets, and incremental improvements in learning algorithms. The figure below illustrates the consumption gap.

These are but three factors, let’s dig deeper.
Not Accessible by Design
When Ed Feigenbaum's expert systems came to life when the IBM 701 was connected to the early ARPANET, the reach was very limited. Only a select few researchers had the privilege of contributing and accessing shared knowledge (which was a massive boost by the way compared to how computing was done). This rhymes well with Christensen's wording of nonconsumption: a potentially transformative technology was out of reach for the vast majority due to restrictions and a lack of infrastructure (in that case, access to the server and the knowledge to evolve and do more research).
In addition to the lack of accessibility, there were multiple “Tech Have-Nots” that the entire field required to grow to something more usable (which is what’s needed for demand to increase).
The "Tech Have-Nots"
The 80s saw a surge of interest in artificial intelligence, but progress was subpar for many reasons:
Limited Internet Access: While ARPANET existed, it was primarily restricted to academic and research institutions. The concept of a globally interconnected "World Wide Web" only started to sprout in the late 80s. This meant that collaboration and knowledge sharing were pretty much confined to small, isolated groups.
Data Scarcity: High-quality datasets were hard to come by, making it difficult to train effective AI models. The concept of "big data" was far off, and the ability to collect and store vast amounts of information was limited. Most
Hardware Constraints: computers of the 1980s had limited processing power and memory (speaking from the future, easy to judge). This made it difficult to run complex AI algorithms, hindering research and development.
The "Haves" and "Have-Nots": Even with access to the limited resources available, significant disparities existed. Well-funded institutions and researchers, like Ed Feigenbaum with his DARPA-backed IBM 701, had an advantage over others who lacked access to such cutting-edge technology.
To put those limitations in perspective, let's have a look at some data and explore NetTalk, one of the first manifestations of Neural networks that was designed to learn how to pronounce written English text.
In the 80s, I’d say NETtalk, with its 18,629 adjustable weights and 1000 data points, was the marvel. It couldn’t do a whole lot though with that much data and those weights compared to a GPT-3, which is when we first realized how powerful neural networks can be when trained on the right amount of data using enough hardware for the outcomes to make sense.

Compared to NetTalk, GPT-3, is a general-purpose model with 175 billion parameters and a trillion data points, an exponential growth in model size over the decades. This is a result of leaps in computational power which was not an overnight quest. In addition to knowledge boosts (e.g., with Transformers), there were many incremental advancements in algorithms, the internet, hardware, and data availability. GPT-3, as the first truly usable form of a language model based on deep neural networks (we had GPT-2, but wouldn’t say that was viable), showcases the difference between a theoretical breakthrough in science and its readiness and commercial variability (i.e., the time, the research, the hardware, the effort it takes to beat nonconsumption).
The AI Spring
Fast forward to the present. Where are we now? Have we solved nonconsumption? Let’s see.
We now have the internet! While not everyone has access to it, compared to the ARPANET in the 80s, about 66% of the world population now (2024) does. It’s still a major issue of nonconsumption on its own, but we made progress! Using the internet, anyone can share, collaborate, and access data/knowledge.
This widespread of the mother internet has led to an explosion of user-generated data, via social media, Wikipedia, articles, and papers, creating large datasets known as "big data". This abundance of data has become the main resource for training today’s AI and large language models, enabling them to learn and improve from diverse and extensive information. Contrast that with the limited availability of data in the 1980s, which was a choke point for further development and advancement of AI and neural networks (NetTalk had a 1k dataset, GPTs datasets are in billions and going trillion).
We have also made progress on the computing front. The development of parallel processing with GPUs and chips specifically designed for AI workloads (e.g., TPUs) has been a game-changer. This leap in computing made it possible to train large and complex deep-learning models on big datasets, which was simply not feasible in the 1980s due to the limitations of hardware at the time.
Research continued, never stopping, which also led to breakthroughs in AI techniques and algorithms. These algorithms, particularly for deep learning and neural networks, have enabled certain applications of AI to automate many of the tasks that only humans were capable of. Techniques such as convolutional neural networks (CNNs) and transformer models have been crucial in getting us to where we are today. In the 1980s, the algorithms were just not as advanced or effective.
In addition to computing, data, and widespread of knowledge, we saw the rise of open-source software which is helping democratize access to AI and machine learning software. Tools and libraries such as TensorFlow, PyTorch, and others are accessible to anyone with an internet connection, allowing for a global participation in AI development. This openness not only accelerates innovation but also reduces the entry barriers that once existed due to proprietary systems. Open source also gave birth to new business models focused on building value not gating IP.
Is it Summer yet then?
Not quite! Despite the improvements, the supply side of compute for AI is still highly inaccessible. Training state-of-the-art large language models requires massive compute resources costing millions of dollars, primarily for high-end GPUs and cloud resources. The costs have been increasing exponentially as models get larger. Only well-resourced tech giants and a few research institutions can currently afford to train the largest LLMs. It actually fits a power law quite nicely, the major players having enough capital and access to data through their current operating business, so you will find that a minority of companies have access to the majority of compute/data (more about the AI market in a previous post).

Additionally, current economics and global tensions around trade policies have led to what is often referred to as a "chip war", impacting the production and distribution of advanced semiconductor chips. This situation introduces disparities in computational access. Countries and companies that can produce or secure these chips have a competitive edge in developing and deploying AI technologies. So yes internet solved some of it, politics always gets in the way 🙂
What about data? According to scaling and chinchilla laws, model performance in language models scales as a power law with both model size and training data, but this scaling has diminishing returns, there exists a minimum error that cannot be overcome by further scaling. That said, it’s not unlikely that we will figure out how to overcome this in the near future.

For a fixed compute budget, an optimal balance exists between model size and data size, as shown by DeepMind's Chinchilla laws. Current models like GPT-4 are likely undertrained relative to their size and could benefit significantly from more training data (quality data in fact). Future progress in language models will depend on scaling data and model size together, constrained by the availability of high-quality data.
Beyond data, and despite the progress, AI still faces technical limitations such as the lack of common sense reasoning, vulnerability to adversarial attacks, and difficulties in generalizing from training data to new, unseen situations, not to mention hallucinations. Finally, current models can be more “creative” than we want them to sometimes, which makes them hard for tasks that require reproducibility or accuracy. So we are not quite there yet.
So is it Disruptive Innovation or AI Winter 2.0?
Generative AI seed funding drops 76% as investors take wait-and-see approach. On one hand, $50 billion has been invested in AI, yet only $3 billion in revenue has been generated. One could argue that this is upfront capital deployed to establish infrastructure and capacity for future earnings (an investment), however, today’s GPUs lose value quickly, especially as newer, more efficient models are continually released, so it’s hard to tell!
This reality is causing investors to pause and reassess their strategies. Past AI hype cycles, like expert systems in the 80s and Japan's 5th generation program early 90s, remind us that overenthusiasm can sometimes lead to disillusionment (see part I of this series).
That said, dismissing AI's potential for disruption would be a mistake. Unlike previous iterations, today's AI, despite its flaws and hallucinations, offers some value (might not be crystal clear, but the productivity gains are not to be reckoned with). This could potentially slow down an "AI winter" as businesses find ways to integrate AI into their workflows, subject to the value perceived.
History repeats itself in a way, we have seen a similar pattern before with the dot-com bubble, where there was a surge of investment in companies, often with inflated valuations and unrealistic expectations, which eventually led to a market correction, with many startup companies failing or being acquired. We're likely to see the same, where the weaker players are likely to struggle and sway away. As discussed in a previous post, existing incumbents and larger players have an existing business model that does NOT revolve around JUST AI, it’s ads, e-commerce, software, consulting, and so on. This gives those bigger players the runway they need to fight the long fight, make bets, and potentially acquire some winners from the new entrant's pool, power law again!
So to answer the original question, I don’t think we will see a “bad” AI winter soon (we might see an autumn but not a winter), at the same time, there is still the debate on whether the current version of AI, though way better than the 80s, qualifies as disruptive innovation on it’s own. I clearly see the potential for AI, the technology, as a disruptive force, but I lean more toward calling the current versions of its application sustaining innovations, especially since we are seeing how it can accelerate and optimize revenue streams of existing incumbent companies as they incorporate it into their pre-existing fly-wheels.
That said, applications that make use of AI to target areas of nonconsumption with more affordable and accessible means to solve problems can unlock new markets, and become disruptive. Here are a couple of examples:
AI as an enabler for personalized education for underserved students in areas where education is infeasible and not accessible.
AI-powered diagnostics expanding healthcare access in developing countries where healthcare is infeasible and not accessible.
The question becomes whether the tech powering today’s AI is enough to give birth to those disruptive innovations (the data, the compute...). I’d say not yet, what say you?
That’s it for this series! If you want to collaborate, co-write, or chat, reach out via subscriber chat or simply on LinkedIn. I look forward to hearing from you!