
Beyond LLMs: Compounds Systems, Agents, and Whole AI Products
A Framework for Building Great AI Products

Introduction
The other day, I found myself reflecting on a classic concept that I was taught in business school, Maslow’s hierarchy of needs, a simple but powerful framework for understanding human motivation, with basic physiological needs at the foundation (air, food, water, shelter, sleep, clothing,...) and the pursuit of self-actualization at the pinnacle.

This got me thinking, in the world of tech (especially AI) and products, what is an equivalent? I mean, users always have needs, and needs in the product vary significantly subject to the use case and the problem being solved, but a spectrum definitely exists. Is there a model or a framework we can use to identify what constitutes the “right” product for customers and what customers would expect of the product? Luckily, Geoffrey Moore's "Crossing the Chasm" provides some answers. In his book, Moore references Levitt’s Whole Product Model, and goes further to simplify by introducing the “Simplified Whole Product Model”.

In this post, we will internalize Moore's model, expand it, and show how it can be applied specifically to AI products (applies to any product as well). We'll dive into the trade-offs inherent in building AI applications and illustrate these concepts with real-world examples.
My goal is that after you read this post, you should have a mental model and a framework for building great/usable AI products, which would help you not only think about the technology, but also how it fits in the big picture.
The Whole Product Primer (Plus it’s Descendants)
The "Whole Product" model revolves around the idea that a core/generic product must be complemented by additional services and interfaces (aka enablers) making up the Whole Product which should provide a solution to the customer’s problem and to address their needs.

In Geoffery Moore’s book, the core/generic product is defined as the fundamental offering or technology that a company produces, which may not be sufficient to fully solve the customer's problem or meet their needs.
This is where the outer ring comes into play. It represents the whole (expected) product, which is divided into sectors. This outer ring encompasses all the additional elements that customers expect or require to make the core product fully functional and valuable to them, let’s call them the “enablers”.
The Adapted (Simplified) Whole Product Model
In the tech industry, companies often prefer to build upon existing open-source projects or technologies rather than developing everything from scratch. These companies focus on adding unique value through layers of customization, support, consulting services, integrations, and proprietary patterns, creating a whole product that is more than the sum of its parts.
Furthermore, any successful technology is bound to become commoditized over time, a strategy we often see in tech employed by competitors who gain from doing so, forcing value into higher layers in the value chain (which they usually have thus wanting to commoditize). Recognizing this, companies need to continually innovate and differentiate their offerings to maintain a competitive edge (related, see a previous post on AI market dynamics and what companies in the space focus their efforts on).
Therefore, let’s adapt the simplified whole product model with two key adjustments. First, we'll shift from fixed sectors to a more modular, petal-like structure. This reflects the interconnected yet distinct components that comprise the whole product layer. Second, we'll introduce a new layer above the whole product layer, called the "differentiated product layer". This layer will highlight the unique value propositions that set companies and their products apart, showcasing how they create the most value for their customers.
To be more concrete, let’s show how this can be applied to Slack for example (this is just for illustration purposes, the real differentiators could very well be very different).

In addition to representing the product's enablers differently using petal-like modular components, we added a new layer to highlight the differentiators. In the example above and in the case of Slack, enablers could be threads, Slack Connect, the workflow builder, and/or Slack AI.
We are very close to being done here with the adaptations, so we will add one last thing to our new framework. In addition to the differentiated layer, we would like to model customizability for products. I.e., one customer's whole product may not be the same for another. I.e., not all customers desire exactly the same features, so it’s important to cater based on customers' constraints/needs. For example, generically, some customers value safety/security over cost, others might value speed, etc.

Let's continue the slack example. Slack might have different customers to cater for. Enterprise customers, use it mainly as a means for company-wide communication, in that case, the focus will be security and compliance with the company’s communication policy, leading to:
Prioritized Enablers: Enterprise-grade security, granular permissions, compliance features (e.g., data retention policies)
Emphasized Differentiators: Slack Connect for secure external collaboration, integration with enterprise security tools
Another use-case, focus area might be on developers, and Slack being part of their dev/test workflows. In that case, the focus will be on developer productivity and collaboration, leading to:
Prioritized Enablers: Integrations with development tools (e.g., GitHub, Jira), code snippets, powerful search
Emphasized Differentiators: Workflow Builder for automating tasks, Slack AI for code suggestions and knowledge retrieval

The takeaway here is that versatility can be a core differentiator on its own because it allows for tailored product experiences. Another way to look at it is that the constraint being imposed defines the core value proposition of the product and how it is shaped to best serve and differentiate in a particular space.
In our example, Slack can tailor its offering to different customer segments, highlighting the features and capabilities that are most relevant to each group. This customization not only enhances the user experience but also strengthens Slack's value proposition in a competitive market.
Towards Whole AI Products (aka Systems)
Hopefully, you have a handle on the adapted simplified whole product framework by now. Next, we will focus on using the framework and mapping it to the super exciting world of AI applications.
Key Ingredients to Building AI Applications
Before the mapping, let's do a quick primer on the core ingredients of AI products and applications (a sample not an exhaustive list). We will cover the key ideas, but we won’t delve into the technical intricacies. For that, there are many resources available, some of which I will be referencing as we go for further reading.
LLMs AND/OR SLMs
In a previous post, I introduced the model product possibilities frontier, a framework for studying the tradeoffs and use cases of large language models (LLMs) and Small Language Models (SLMs), which I will not be repeating here for brevity. That said, the choice of which models and their size to use is a key ingredient for building generative AI applications and products.
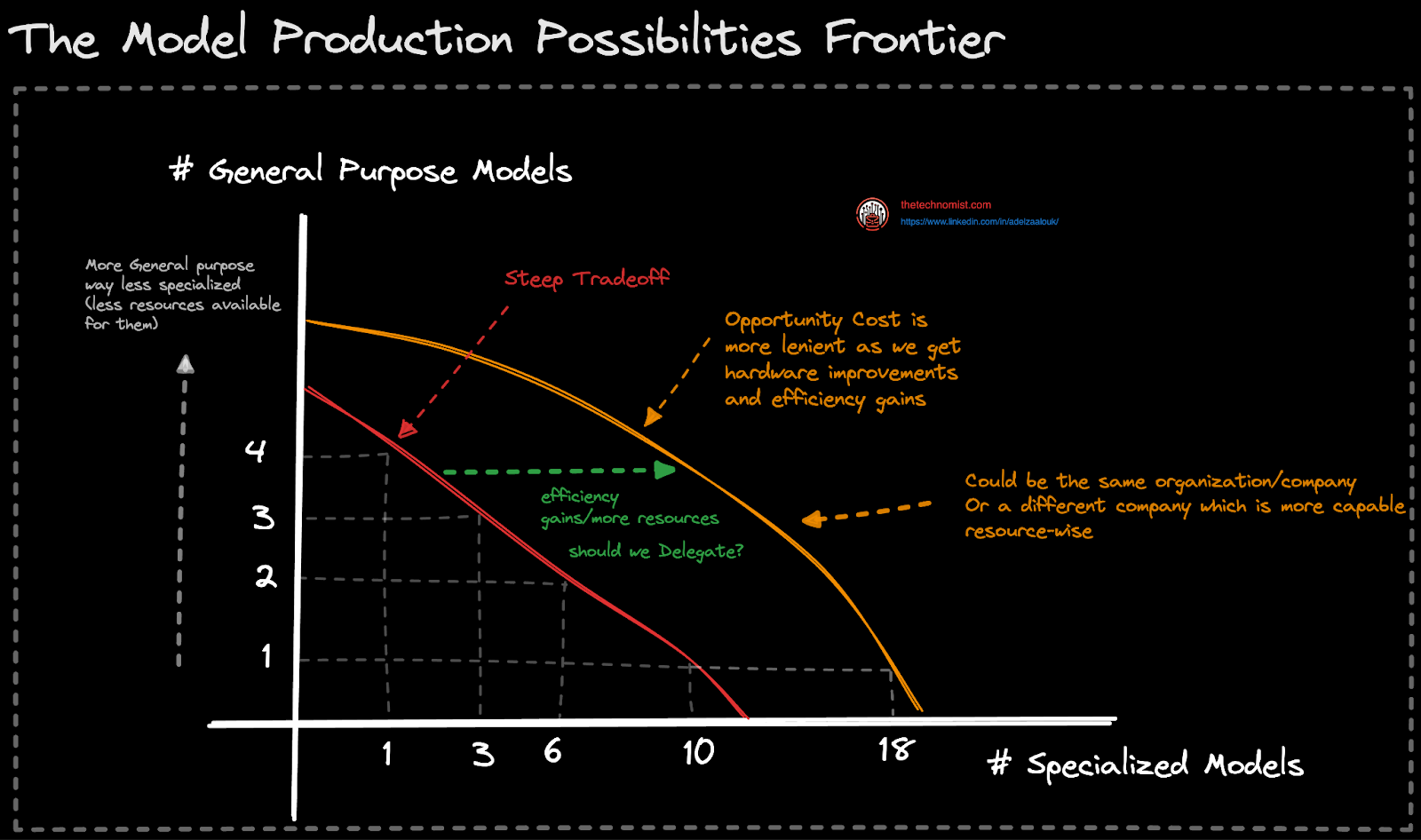
Here are a few considerations/questions to ask yourself when reasoning about the tradeoffs:
What are your most favorable constraints? Is it speed, quality, cost, etc?
What about privacy? Do you value data staying in-house (Small models are easier/cheaper to deploy, train, and serve on-premise)
How are you going to evaluate the performance of your AI applications that make use of these models?
Is a smaller model easier to test and evaluate (think about the specificity as truth vs the versatility of LLMs which introduces more variability/hallucination, and thus makes it harder to test)

While we did not call it out explicitly, large or small models can be fine-tuned and aligned. This is covered in greater detail in this post.
Retrieval Augmented Generation (RAG)
I’d say 2023 was the year of RAG. We went from naive RAG to Advanced RAG. I liked naive tbh, it communicated simplicity, but well, these days advanced is perceived as better, something we are yet to fix, but that’s a different story 🙂. This paper provides more details.
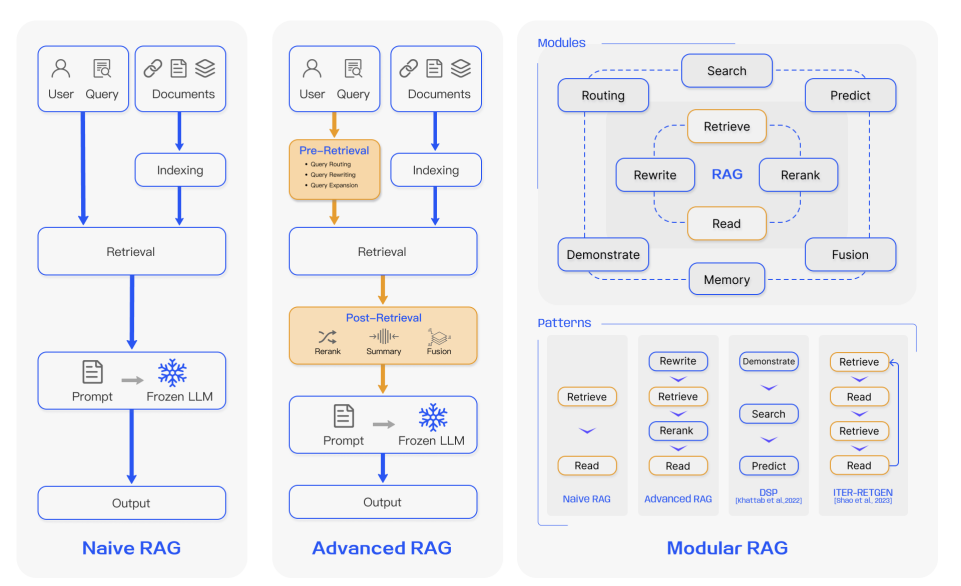
RAG workflows are comprised of many moving pieces and optimizations. The goal is to retrieve the best content to augment the context for LLMs (text generation) with necessary information. In that case, LLMs become curators rather than innovators/generators of sorts (they shape the retrieval results and make them relatable as an output to a user but are not the source of knowledge themselves). To give you an idea of the moving pieces involved with RAG, here is a rough brain dump (feel free to surf the mindmap as you please, I will not enumerate the details here for brevity).

When considering RAG for building AI applications, some questions come to mind around tradeoffs and decisions, usually between RAG, long context, and Fine-tuning. Again, we won’t cover details, but here are a set of questions that you can ask to inform your decision.

Does the application require access to external data sources to provide accurate and up-to-date responses (RAG usually makes sense if data freshness is important, especially since language models are point-in-time trained)?
Is it crucial for the model to adapt its behavior, writing style, or domain-specific knowledge to match specific requirements (RAG does not customize behavior, fine-tuning would make sense if behavior customization is a goal)?
How critical is it to minimize the risk of the model generating false or fabricated information (hallucinations)?
How much labeled training data is available for fine-tuning? Does it adequately represent the target domain and tasks?
How frequently does the underlying data change? How important is it for the model to have access to the latest information?
Is it important to understand the reasoning behind the model's responses and trace them back to specific data sources?
How important is minimizing computational costs for your project or organization?
Do your typical queries require multi-step reasoning (complex queries or simple questions)?
How important is the ability to scale your solution to handle a large number of queries?
Finally, here is a short guide I created to help you make informed decisions about RAG/Fine-tuning if you wish to use it:
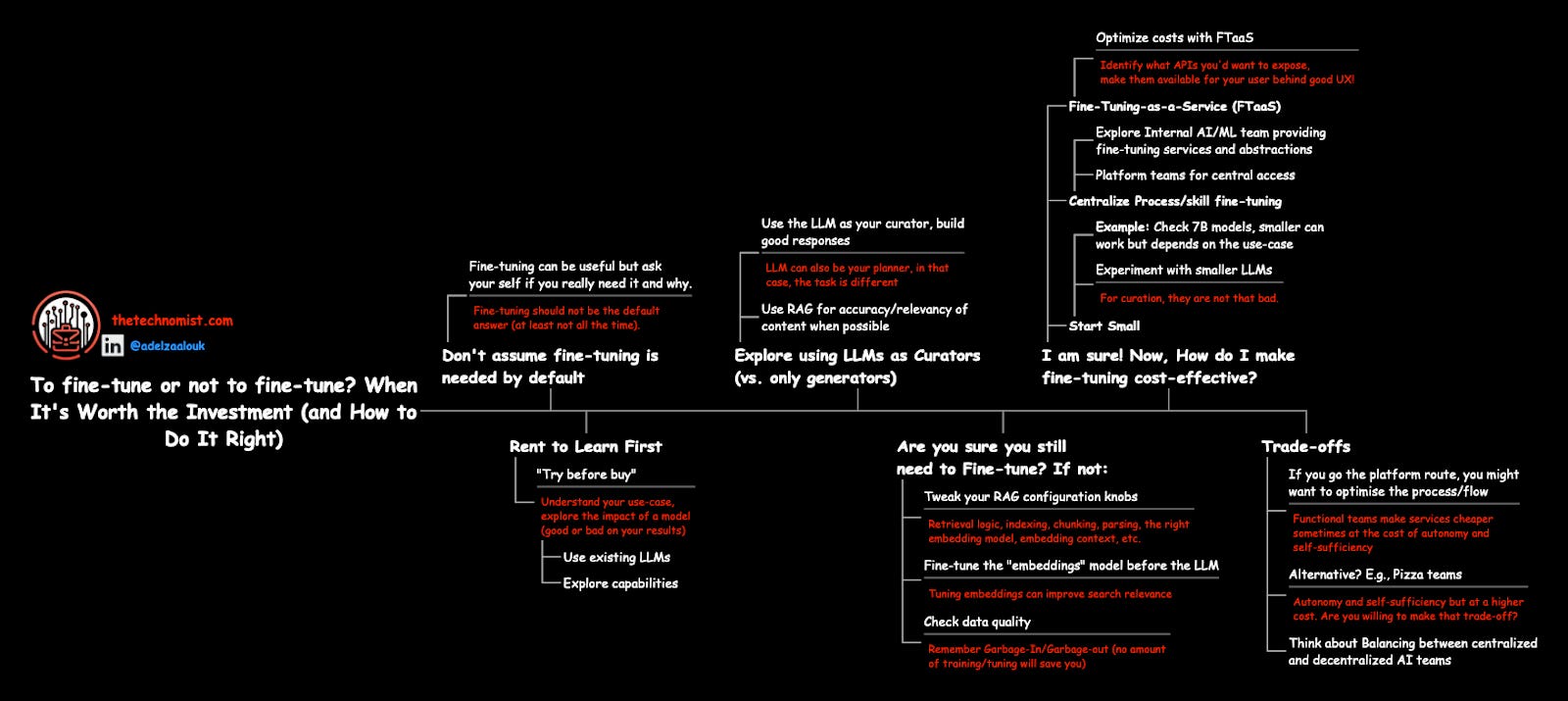
For more information, check the below papers which I found very useful in understanding the differences and the trade-offs:
[2401.08406] RAG vs Fine-tuning: Pipelines, Tradeoffs, and a Case Study on Agriculture
[2312.05934] Fine-Tuning or Retrieval? Comparing Knowledge Injection in LLMs
RAG today has become synonymous with building AI applications in some contexts. What’s clear is that RAG is not one component, it's a system comprised of many moving pieces with levers to turn on/off for what makes sense most subject to context and use-case.

Agents ft. Agentic OR Agentless!
In addition to the model (LLM/SLM), RAG, there is the notion of agents and agentic workflows (also agentless to counter 🙂). While this is again not going to be a deep-dive, let’s cover the basics.
What are agents, what is agentic behavior, and why agentless sometimes?

The notion of agents is not new. Agents have existed for decades (see this for examples), they are officially called Intelligent agents. Below is the definition of an Intelligent Agent.
In intelligence and artificial intelligence, an intelligent agent (IA) is an agent acting in an intelligent manner. It perceives its environment, takes actions autonomously in order to achieve goals, and may improve its performance with learning or acquiring knowledge. An intelligent agent may be simple or complex: A thermostat or other control system is considered an example of an intelligent agent, as is a human being, as is any system that meets the definition, such as a firm, a state, or a biome.[1]
What’s changed is that with the advent of LLMs is that agents got a capability boost, from symbolic, rule-based, predefined simple actions with low autonomy (see the history post for more details, you may be reminded of expert systems) to being able to understand and generate natural language, learn and adapt across diverse domains, and perform complex, autonomous actions. In today’s context, An agent is a software entity possessing autonomy, goal-oriented behavior allowing it to operate and generalize cross-domains and take complex actions.
Agentic behavior, in this context, refers to an agent's ability to operate independently, make decisions aligned with its objectives, and execute actions (potentially with tools/functions-calling,...) to achieve those goals. The level of agency can vary based on factors like the complexity of the environment, the agent's goals, and the degree of user supervision required. More agentic systems can operate autonomously in intricate environments, pursue complex objectives, and utilize advanced techniques such as planning and tool use
Finally, there is the notion of flow-engineered / AGENTLESS which relies on determinism and only interfaces with language models for specific clarifying actions, in a sense similar to intelligent agents of the past, with the exception of having access to external intelligence capable of better identifying areas where the predefined action could be taken.
To simplify your life, I've included this visual below (higher resolution here) to help you build a clearer mental picture of agents/agentic.
{kind=link}

Other components
Besides agents, RAG, the models, there are multiple other ingredients that go into building an AI applications, going through each and every one is out of scope for this post, but here is a non-exhaustive list for reference:
Data Pipeline: System for collecting and processing data, think extractions, transformation.
Knowledge Base: where the processed knowledge/data is stored.
User Interface: Web or app interface for users.
Query/prompt Cache: avoid unnecessary query round-trips which can greatly reduce costs.
APIs: To interface with other systems.
Infrastructure: an important component that is usually overlooked, where to host the model/app, how to scale it, etc.
Observability: be able to log, monitor, trace an AI application.
Model Gateways: to interface between the user-query and it’s destination. Along the way, it makes sure the query is authenticated/authorized, masked/audited for sensitive content (e.g., PII), and finally routed to the best model to serve the query (best here is dependent on the use-case, see this post)
<Many more>
As I was writing this, I came across this blog post, which discusses the technical details of some of the most used components for AI applications.
Compounds AI Systems
You have come a long way brave reader, the end is near, and you shall be rewarded. So far we have been separately covering important components and ingredients that are key to the making of AI applications, but what makes the interconnection of these components towards achieving a shared goal? A system!
A system is a group of interacting or interrelated elements that act according to a set of rules to form a unified whole
Zaharia et. al recently introduced the notion of Compound AI Systems. In their post, they define it as:
A system that tackles AI tasks using multiple interacting components, including multiple calls to models, retrievers, or external tools. In contrast, an AI Model is simply a statistical model, e.g., a Transformer that predicts the next token in text.
The authors also emphasize the complexity of designing AI systems:
While compound AI systems can offer clear benefits, the art of designing, optimizing, and operating them is still emerging. On the surface, an AI system is a combination of traditional software and AI models, but there are many interesting design questions. For example, should the overall “control logic” be written in traditional code (e.g., Python code that calls an LLM), or should it be driven by an AI model (e.g. LLM agents that call external tools)? Likewise, in a compound system, where should a developer invest resources—for example, in a RAG pipeline, is it better to spend more FLOPS on the retriever or the LLM, or even to call an LLM multiple times?

In their post, they showcase a table of AI systems, and the components they are composed of. Additionally, they highlight the need for optimization across the chosen components to build reliable AI systems. Below we extract the components mentioned in the post and categorize them into Ops (i.e., operations), Tools, Context/Knowledge, and models.

If you remember in the previous section, we covered similar components and more as ingredients to build AI applications. The takeaway here is that building reliable AI applications takes a system not a singleton component. I.e., “the whole is more than the sum of the parts”
Another way to visualize it is to consider a dashboard looking like a cockpit with all knobs needed to build your AI application, here is an example of what that could look like:

Without abstraction, you’d have to configure all these knobs manually (i.e., you’d have to understand what each of these means). Nowadays, there exist many frameworks to do the orchestration which to a good extent abstracts away some if not all these details. Is that a good thing? I will let you decide. My take? It can be a good thing if you are experimenting, learning, but if reliability, performance, and security are concerns (and they should be), you’d still have to understand what all these knobs mean before you pick up automation/orchestration tooling. Think of it this way, do pilots just take on their license without understanding what each and every knob in their cockpit means? I would guess not! But when they do, they can auto-pilot if they choose to because at any point they CAN switch back to pilot-mode and turn on the right knobs to fly the plane safely.
From Compound Systems to Whole AI Products
Now that we understand the key ingredients needed to build AI applications and compound AI systems, which is the technical pattern we will use to describe the components of an AI application and how they intermingle, let’s go ahead and map that back to our adapted simplified whole product framework.
Note: While having a technical system encapsulating the main function(s) of the product is great, shipping and building whole products take more time/effort (to execute) than the technical parts.

As you can see in the diagram above (higher resolution here), we took the components of compound AI as we categorized them in the previous section, and mapped them to the generic/core (right in the middle), and the whole product layer comprised of one or more enablers. You may notice that we left out the differentiated product layer, that’s intentional. We will cover that in a coming section. What about the constraints? Let’s model them as well well.
{kind=link}
The constraints will heavily depend on the use-case, I used “Enterprise” here as an example. For enterprise AI use-cases, safety, and reliability are important concerns. Using the constraints, we put emphasis on specific parts of the whole product, highlighting key enablers. In that case we chose legal, ops, gateway, and UX.

Different use-cases will place different emphasis on the whole product, resulting in some layers being more important than others. Some use-cases even simplify the whole product by losing unneeded enablers, making the whole product leaner and more directed towards solving the problem/use case at hand.
Defensibility AND Compound MOATS
Previously we took a tour to compare and contrast the current AI Market Landscape. We showed how companies that have a mission to better something other than just the model might have better odds in surviving in a competitive market (I.e., AI as an enabler vs. AI as the core product). We have also shown how companies are releasing open-source language models, which increases competitiveness and commoditizes the model layer completely making it pertinent for startups and companies to see defensibility through differentiation, i.e., what is the company’s MOAT?

For defensibility, let’s summarize the most prominent strategies:
Having strong using communities and strong user engagement.
Transitioning from Foundational Models to Purpose-Based Approaches
Building Layers of Value Beyond the Model
Differentiating at Various Layers of the AI Stack
Let’s briefly get into each.
Fostering a strong community and high user engagement: This involves cultivating a rapidly growing user base, harnessing the power of network effects, and creating a vibrant community that engages users across different generations. I.e., Who will use my product, what value to I provide beyond just the model, and why do I have a community in the first place?
Transitioning from general foundational models to purpose-built applications: By focusing on specific user needs and problems, companies can tailor their AI solutions to provide more value and differentiate themselves in the market using existing business models, E.g., I already a social network, I make good money from Ads, how can I add more value to the existing community by incorporating AI?
Building layers of value beyond the model: Invest in research to continually improve models and applications, leverage proprietary data (data as moat) for enhanced performance (after all garbage in, garbage out, gold in, gold out), and continuously refine products based on user feedback. By building a loyal customer base and offering unique value propositions, companies can establish a strong competitive advantage.
Differentiate by focusing various layers of the AI stack: This can involve developing superior AI models or smaller niche models (focusing on a tiny use-case but beating anyone else at doing it), providing scalable and efficient AI infrastructure, or creating user-friendly interfaces and seamless integrations (a GPT store, for example?). Each layer presents an opportunity for differentiation and can contribute to a company's overall defensibility.
These are just but some strategies that can be used to build moats, it is rarely a single component, it’s the sum of multiple to make a better whole defensible product. Compound MOATs ™ are the way! The last strategy is the one with lowest chances of surviving alone, so I’d consider at least two of the above strategies to start differentiating. Some questions to ask:
What processes do you have in place to ensure that AI models are being leveraged as enablers rather than being treated as end products?
What strategies are you employing to rapidly grow your user base, create network effects, and foster a sense of community?
What investments are you making in research, data, product refinements, and customer acquisition to build layers of value?
What resources are you allocating to differentiate your company at the model layer, infrastructure layer, or application layer
How are you evaluating and prioritizing potential areas of differentiation to ensure a sustainable competitive advantage?
Adding The Differentiated Product Layer
Alright alright alright, now that we understand moats/defensibility strategies, how do we model them back into our framework?! Using any (or additional) defensibility strategies to differentiate, additional components are added to the differentiated product layer in the model. In that case, we added strong community, integration with partners, a store/marketplace, innovations at the application layer (value above the model), and unique data. This layers makes a company’s set of Compound MOATs, which are also what create brand differentiation, loyalty, retention, etc.

AI Whole Products in Practice
It’s 2024, almost two years after the release of ChatGPT, almost 70 years after the perceptron, the first manifestation of neural networks (see this post for more details), and ~40 years after the creation of expert systems which was the closest Applied AI could get. In the post, I go into the details of why expert systems did not pan out (and partially led to an AI winter), but for brevity, it was a consumption gap, what we had back then in terms of compute, community, and technology was a far cry from where we are today.

With LLMs showing a glimpse of what can be achieved with natural language, and with the maturity of predictive AI and deep neural networks, applied AI is a reality now more than ever. In this section, we show hope AI applications are built using compound AI systems in the wild. There are many sources of knowledge about applications of AI that can be found on the internet. I chose to use the Federal AI use-case inventory to extract some examples use-cases, followed by a real case of how Uber and OpenAI make use of compound AI systems to build whole AI products and map them to our adapted simplified whole product framework.
Federal AI Use-Cases Examples
Below is the breakdown for 6 example use-cases from the inventory after we have applied the framework (use the codes to find them in the inventory).
Note: Higher resolution of the image below can be found here.
{kind=link}

Example 1: TowerScout (HHS-0022-2023)
Problem: Identifying potential sources of Legionnaires' Disease outbreaks during investigations.
Constraints: Accuracy, speed of detection, ability to process aerial imagery.
Core Product: Object detection and image classification models trained to recognize cooling towers.
Enablers:
Data Pipeline: System to acquire, process, and store aerial imagery.
Knowledge Base: Geographic data on building locations, potential water sources.
Tools: Image annotation tools, model training infrastructure, visualization software (GIS).
Differentiated Product Layer:
Integration: Direct integration with CDC outbreak investigation workflows and databases.
Unique Data: Access to CDC's epidemiological data for model training and validation.
Example 2: USDA Cropland Data Layer (USDA-0026-2023)
Problem: Classifying crop types and land use for agricultural monitoring and statistics.
Constraints: Accuracy, national coverage, consistency over time, ability to handle satellite data.
Core Product: Machine learning algorithms (likely Random Forest) trained to classify crops from satellite imagery.
Enablers:
Data Pipeline: System to acquire, process, and store multi-temporal satellite imagery.
Knowledge Base: Ground truth data from farm surveys, historical crop patterns, weather data.
Tools: Image processing software, model training infrastructure, geospatial analysis tools.
Differentiated Product Layer:
Long-Term Data: Historical CDL data provides valuable insights into agricultural trends.
Public Availability: Open access to CDL data makes it widely used by researchers and policymakers.
Example 3: Human Resource Apprentice (OPM-0000-2023)
Problem: Time-consuming and potentially subjective evaluation of applicant qualifications in government hiring.
Constraints: Accuracy, fairness, ability to process applicant resumes and job descriptions, explainability.
Core Product: AI model (NLP and potentially ranking algorithms) trained on data from previous hiring decisions.
Enablers:
Data Pipeline: System to acquire and process applicant data from applications and resumes.
Knowledge Base: Job descriptions, qualification requirements, competency frameworks.
Tools: NLP libraries, model training infrastructure, user interface for HR specialists.
Differentiated Product Layer:
Bias Mitigation: Robust testing and evaluation for fairness and adverse impact mitigation.
Explainability: Ability for the system to provide clear rationale for applicant rankings.
Example 4: HaMLET (Harnessing Machine Learning to Eliminate Tuberculosis) - HHS-0023-2023 (CDC)
Problem: Improving the accuracy and efficiency of overseas health screenings for immigrants and refugees, specifically for tuberculosis.
Constraints: Accuracy, speed (high throughput), ability to process chest x-rays, potential resource limitations in overseas settings.
Core Product: Computer vision models trained to detect TB from chest x-rays.
Enablers:
Data Pipeline: System for acquiring, digitizing, and storing chest x-rays.
Knowledge Base: Large, labeled dataset of chest x-rays with confirmed TB diagnoses.
Tools: Image annotation tools, model training infrastructure, potentially lightweight deployment for use on less powerful devices.
Differentiated Product Layer:
Public Health Impact: Potential to significantly reduce TB transmission and improve global health outcomes.
Resource Efficiency: Automating screening can reduce the need for specialized personnel, making it more feasible in resource-constrained settings.
Example 5: RelativityOne (DHS-0026-2023 - Dept. of Homeland Security)
Problem: Inefficient and time-consuming document review in litigation, FOIA requests, and other legal processes involving large volumes of documents.
Constraints: Accuracy, speed, ability to handle diverse document formats, legal and ethical considerations around data privacy and access.
Core Product: A document review platform using machine learning techniques (continuous active learning, clustering).
Enablers:
Data Pipeline: System for ingesting, processing, and indexing large volumes of documents.
Knowledge Base: Legal frameworks, case law, and other relevant information for model training.
Tools: Text extraction and analysis tools, user interface for legal professionals to review and manage documents and results.
Differentiated Product Layer:
Enhanced Efficiency: Significantly reduces the time and resources required for document review.
Improved Accuracy: ML models can identify relevant documents and patterns that humans might miss.
Compliance and Security: Strong focus on data security and compliance with legal and ethical requirements.
Example 6: Cybersecurity Threat Detection (HHS-0015-2023 - ASPR)
Problem: Effectively analyzing the massive volume of cybersecurity threat data to identify and respond to real threats.
Constraints: Speed, accuracy, ability to handle diverse data sources, evolving nature of cyber threats.
Core Product: AI and ML models trained to detect anomalies and malicious activity in network traffic and other security data.
Enablers:
Data Pipeline: Real-time data ingestion from various security tools (firewalls, intrusion detection systems, etc.)
Knowledge Base: Databases of known threats, attack patterns, and vulnerabilities.
Tools: Data visualization and analysis tools, security orchestration and automation platforms for incident response.
Differentiated Product Layer:
Proactive Threat Detection: AI models can identify emerging threats and zero-day attacks that traditional rule-based systems might miss.
Automated Response: AI can automate incident response actions, such as quarantining infected devices, to contain threats faster.
Companies & Products
Beyond the federal AI use-cases, let us apply the framework to products released out in the open by well-known companies and startups. We will be covering Uber, and OpenAI.
Uber’s Michael Angelo
Recently, I came across this post and this post covering Uber's journey in developing and refining their AI platform, Michelangelo, over the past 8 years. According to the posts, Michelangelo plays a critical role in powering nearly every aspect of Uber's operations, from core functions like ETA prediction and ride matching to fraud detection and customer support. Additionally, since 2023, Uber has been building various internal generative AI applications and platforms to provide a good foundation for building those applications (see this post on how to build platforms for more details). Here is a distribution of their generative AI use-cases/goals:

With that in mind, let’s apply our adapted whole product framework to Uber’s internal AI use-case with Michaelangelo and building an AI platform.
Problem: Lack of a standardized and scalable system for developing, deploying, and managing ML across Uber's diverse business needs with tiering/prioritization.
Goal: Harness the power of both traditional ML and LLMs to improve core operations (ETA, pricing), enhance user experiences (customer support, app features), and boost internal productivity.
Constraints:
Scale: Managing massive data volume and real-time prediction demands of a global user base.
Latency: Delivering low-latency predictions for time-sensitive applications.
Security & Privacy: Protecting user data, particularly PII, especially when using external LLMs.
Collaboration: Supporting efficient workflows for diverse teams of data scientists, ML engineers, and application developers.
Adaptability: Rapidly evolving to integrate new AI/ML technologies and adapt to the changing landscape.
Cost-Effectiveness: Managing the computational expenses of large-scale AI, optimizing where possible.
Core Product: Fine-tuned / Custom self-hosted LLMs tailored for Uber’s internal use-cases.
Enablers:
Data Pipeline:
Palette: Feature store for managing, sharing, and accessing features across Uber.
Data Processing & Prep: Tools for collecting, cleaning, and transforming data for both traditional ML and LLMs.
Knowledge Integration: Connecting LLMs to knowledge bases, APIs, and Uber-specific data sources for grounding and context.
Tools:
Development: Michelangelo Studio (MA Studio) for UI-based workflows; Canvas for code-driven development, version control, and CI/CD.
Training: Horovod, Ray, Spark, support for TensorFlow and PyTorch; specialized tools for LLM fine-tuning and optimization.
Serving: Triton Inference Server, Michelangelo's real-time prediction service (OPS).
Monitoring: Model Excellence Score (MES) for quality assessment, feature monitoring, SLA integration, and LLM performance tracking.
Gateways: Uber’s Specialized Gateways such as (GenAI, CO Inference) abstracting complexities and providing easier access to AI capabilities.
User Interfaces: Michelangelo Studio: Unified UI for managing ML workflows.
Legal & Operations:
Security & Compliance: PII redaction, access controls, bias detection, and mechanisms for ensuring responsible AI usage.
Cost Management: Tracking LLM usage, setting budgets, and implementing cost optimization strategies.
Model Versioning & Artifact Management: Ensuring reproducibility, tracking experiments, and managing model deployments.
Differentiated Product Layer:
Scale and Operational Efficiency: Michelangelo and its integrated gateways are built to handle the complexities of AI/ML at Uber's global scale.
Internal Platform Expertise: Uber's AI platform team has deep knowledge of the company's unique data, business needs, and engineering environment.
Focus on Developer Experience: Tools like MA Studio and Canvas, combined with the abstraction layers of gateways, prioritize developer productivity and ease of use.
Hybrid Approach: Combining traditional ML and LLMs through a unified architecture allows Uber to address a wider range of use cases.
If you have noticed, and in the mapping we have done so far for Michael Angelo, the whole product is the platform. It’s what enables developers to build products that customers love, take their mobile application for example. I have discussed platforms as products or products of the platforms in more length in this post. Feel free to take a refresher trip if you are looking for more details on the distinction.
OpenAI’s ChatGPT
By now you most likely have used a variant of ChatGPT, what you have not seen is what’s running under the hood to allow you to use the interface exposed and get the chat experience you get. Below is a diagram from an OpenAI talk about what the platform looks like under the hood and what it takes to run ChatGPT and expose to the world.

To get more visibility, let’s apply the adapted whole product framework to ChatGPT :
Problem: How to providing accessible, versatile, and powerful AI assistance for a wide range of tasks and queries.
Constraints:
Safety and ethical considerations
Scalability to handle massive user demand
Accuracy and reliability of outputs
Cost-effectiveness of compute resources
Core Product: Large Language Models (GPT series)
Enablers:
Models: GPT-3.5, GPT-4, and other specialized models
Context/Knowledge: Fine-tuning datasets for specific tasks and safety alignment
Tool-use
ChatGPT for general conversation and task assistance
DALL-E for image generation
Codex for code generation and understanding
UX: the ChatGPT web interface + the Mobile app
Ops:
Scalable infrastructure for model training and inference
Monitoring and logging systems
User feedback collection and analysis
Differentiated Product Layer:
GPT Store: Marketplace for custom GPTs created by users and organizations
Strong Community and User Engagement: Rapidly growing user base for ChatGPT as well as an active developer community using OpenAI API (in a sense it’s become the standard)
Continuous Model Improvements: Regular updates (e.g., GPT-3 to GPT-4) and Integration capabilities with other tools and platforms
State-of-the-Art Performance: Leading performance in various language tasks
Unique Data and Feedback Loop:
Massive web-scraped dataset for pre-training
Vast amounts of user interaction data for model improvement
Innovation at Application Layer:
GPT-4 with visual input capabilities
ChatGPT plugins ecosystem
Realistic Voice with imitation
Assistant API for creating AI agents
Strategic Partnerships: Microsoft partnership for exclusive access to GPT models increasing distribution blast radius to all Azure users.
Infrastructure: Access to large-scale infrastructure and compute (partially enabled by the Microsoft partnership as well)
The (Adapted) Market Development Life Cycle
So far we have been traveling across the lands of the adapted simplified whole product framework. Along the way, we have also covered some real examples to demonstrate how the framework is (or can be) used. It wouldn’t be a whole product framework adaptation if we didn’t adapt it to Moore’s Market Development Life Cycle model though.
Note: higher resolution of the image below can be found here.
{kind=link}

It all starts with a Generic (core) Product, a barebones model appealing to innovators/techies who prioritize core functionality. If you would pick an open-source LLM (maybe fine-tuned to solve a specific problem?) and just put it to the test, that would be an example of a core/generic product (the enabling technology which is at the heart of making a future whole product possible). Innovators here are tinkering with the tech that you seemingly are building your product around (or that you might have built yourself). Questions they might ask here: how does it fair, do we need it, do we have better alternatives, would we require additional support (skill/knowledge?), do they (your company) have it?... you’ll neeed to make sure you have answers to those questions.
To cross to the Early Adopters and their desire for somewhat practical solutions, your product should find a way to meet the expectations (aka the Expected Product), for the problem your customer is trying to solve, what are some of the key enablers you made sure to add to create a Minimum Viable Product (MVP)? Here you must have started to target a specific niche, and started to provide enough enablers in the product that it solves 80% of their use-case (they might be willing to help because now they SEE the value of what you are offering). At this stage, relationships and feedback matter.
Now it’s the moment of truth, to cross the chasm to the early majority. This stage often makes or breaks your product/value prop. You will have to navigate a tradeoff: maintain the speed and innovation that attracted early adopters while at the same time also addressing the reliability/demands to make this product Whole. Make no mistake, the likelihood of others doing the same is high at this stage, but you will need to cross here anyways. Examples of enablers at this stage:
An efficient pipeline for data acquisition, processing, and storage. Think of Uber's Michelangelo platform, with its specialized data management tools like Palette.
User-friendly interfaces, efficient model training infrastructure, observability (think compound systems here, and tailor to constraints). Using our Uber’s example, think Michelangelo Studio and their AI gateway (AuthN/Z, routing, etc).
Knowledge Integration, connecting the AI to relevant knowledge bases (RAG maybe), well-defined APIs, and domain-specific data sources to enhance its capabilities.
Once you do cross, know you have augmented your product just enough to make it whole, welcome to the land of the pragmatists, and congratulations, you have an augmented whole product with well-defined key-enablers that solve the customer’s problem.
You are not done though! Now you get a chance to tell the world why you are different, ruffle your feathers, and be ready to differentiate, welcome to the Differentiated Product layer. At this stage, you’ll need to focus on highlighting your unique value proposition and solidify your maots. Examples here could:
Foster an active community around the product (if you have that already, you might be a winner) and encourage user contributions/feedback. Both Slack and OpenAI have cultivated vibrant communities around their products (there are different ways to do that, but that’s not the topic of this post maybe more on this later).
Collaborate with key partners to expand reach, access valuable resources, and enhance the product’s capabilities. For example, OpenAI's partnership with Microsoft exemplifies this, granting them access to compute and distribution,
Leverage unique datasets, if you have a community, you likely also have data unique to your products/services (with consent of course I hope). Develop and customize your models, and refine your core optimizatoions to create a competitive edge. Uber's Michelangelo leverages their vast ride-sharing data and internal expertise to optimize AI for their specific business needs.
As you move through the stages, you’ll notice how the product's complexity increases, natural and reflects the evolving needs and expectations of each customer segment/use-case. The visual above hopefully acts as a guide/framework to highlight the importance adapting your AI product strategy accordingly to achieve success in each phase of the lifecycle. Failing to adapt will leave you behind, while successfully listening and continuously building/iterating can give your company and your product a boost into a temporarily blue-ocean (we will talk about that later) where you excel for what you do.
Putting it All Together: Building Whole AI Products
You MADE IT! By now, you understand what it takes to build whole AI products! Let’s quickly recap.
In this post, we went together on a journey that started from classic business principles like Maslow's hierarchy of needs to the world of compound AI systems AND how they map and transform into whole AI products. We've explored the critical components of successful AI products and applications, adapting Moore’s "Simplified Whole Product Model" along the way, and finally fitted our new framework into Moore’s infamous Model Development Lifecycle framework (again with some adaptations/opinions). Here are some take-aways from our journey:
It's Not Just About the Model: While LLMs and SLMs are powerful (open-source or not), they are just one ingredient in the recipe for a successful AI product. And yes open source unlocks many potential benefits (out of scope), but it does NOT mean it rivals whole products!
Compound AI Systems make a good pattern/foundation for whole AI products: The true power of AI is unleashed when you combine models, data pipelines, knowledge bases, retrieval mechanisms (like RAG), agents, user interfaces, and robust infrastructure (and more) into a cohesive system that works well with the defined constraints.
Differentiation is key: In a rapidly evolving AI landscape, establishing a moat (see above) is essential for long-term success. Focus on building strong communities, transitioning to purpose-built applications, creating value beyond the model, and differentiating at various layers of the AI stack. Compound MOATs (read above) are the way to go!
Constraints Shape Your Product: Clearly define the problem you're solving and the specific constraints of your target audience. These constraints will guide your choices regarding the core product, enablers, and even the differentiators.
The Adapted Whole Product Framework Provides a Roadmap: By considering each layer of the framework, the generic/core product, enablers, constraints, and differentiated product layer, you can develop a complete understanding of what constitutes a valuable and defensible AI product.
Building AI products is not a one-size-fits-all endeavor. The examples from the Fed-AI use-case inventory, Uber’s Michaelangelo, or OpenAI’s ChatGPT (some of many examples in the wild) highlight the different approaches and strategies companies/institutions are employing today to build AI products and applications. By focusing on user needs, and continuously innovating/iterating/discovering, you can navigate the uncertainties of the AI landscape and create AI products that truly deliver on their promise.
With all that said and done, now It's Your Turn, friend:
Think about an AI product you are working on or envisioning. Use the adapted simplified whole product framework and the guiding questions posed throughout this post to analyze its strengths, weaknesses, and opportunities for differentiation. Remember, building successful AI products requires building a perspective that goes beyond just the technology itself, remember the “whole is greater than the sum of it’s parts”, so make sure how you connect the parts resonates will with your brand, mission, and strategy.
That’s it! If you want to collaborate, co-write, or chat, reach out via subscriber chat or simply on LinkedIn. I look forward to hearing from you!
A bit complicated for me but loving the efforts!..Whats your background?